Commits on Source (153)
- 53 additional commits have been omitted to prevent performance issues.
Showing
- .gitlab-ci.yml 5 additions, 2 deletions.gitlab-ci.yml
- _static/epilog/external.links 44 additions, 0 deletions_static/epilog/external.links
- conf.py 14 additions, 4 deletionsconf.py
- guides/index.rst 4 additions, 4 deletionsguides/index.rst
- guides/mentor.rst 5 additions, 5 deletionsguides/mentor.rst
- ideas/index.rst 21 additions, 43 deletionsideas/index.rst
- ideas/old/automation-and-industrial-io.rst 8 additions, 6 deletionsideas/old/automation-and-industrial-io.rst
- ideas/old/deep-learning.rst 42 additions, 0 deletionsideas/old/deep-learning.rst
- ideas/old/fpga-projects.rst 23 additions, 0 deletionsideas/old/fpga-projects.rst
- ideas/old/index.rst 0 additions, 2 deletionsideas/old/index.rst
- projects/2024.rst 109 additions, 0 deletionsprojects/2024.rst
- projects/index.rst 6 additions, 0 deletionsprojects/index.rst
- proposals/2024/aryan_nanda/images/Figure1.png 0 additions, 0 deletionsproposals/2024/aryan_nanda/images/Figure1.png
- proposals/2024/aryan_nanda/images/Figure2.png 0 additions, 0 deletionsproposals/2024/aryan_nanda/images/Figure2.png
- proposals/2024/aryan_nanda/images/Figure3.png 0 additions, 0 deletionsproposals/2024/aryan_nanda/images/Figure3.png
- proposals/2024/aryan_nanda/images/Figure4.png 0 additions, 0 deletionsproposals/2024/aryan_nanda/images/Figure4.png
- proposals/2024/aryan_nanda/images/Figure5.png 0 additions, 0 deletionsproposals/2024/aryan_nanda/images/Figure5.png
- proposals/2024/aryan_nanda/images/Figure6.png 0 additions, 0 deletionsproposals/2024/aryan_nanda/images/Figure6.png
- proposals/2024/aryan_nanda/index.rst 601 additions, 0 deletionsproposals/2024/aryan_nanda/index.rst
- proposals/2024/ijc/index.rst 302 additions, 0 deletionsproposals/2024/ijc/index.rst
_static/epilog/external.links
0 → 100644
projects/2024.rst
0 → 100644
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
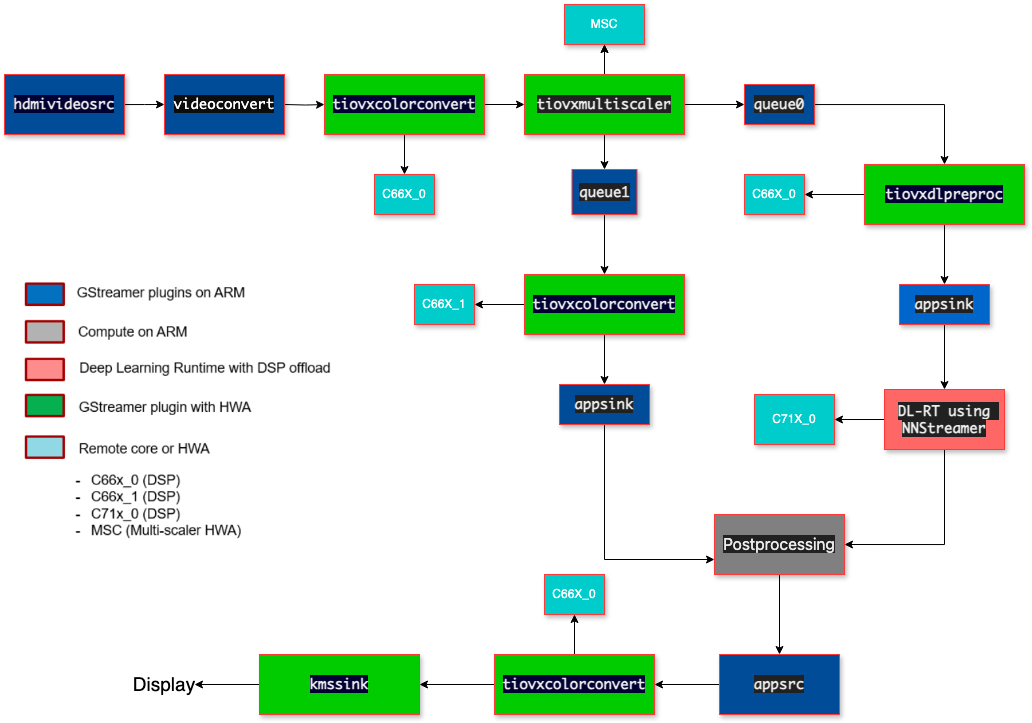
211 KiB
{kind=link}
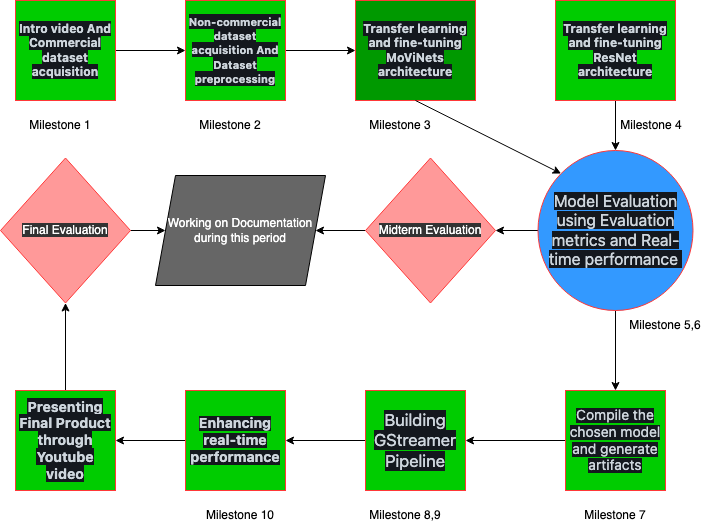
108 KiB
proposals/2024/ijc/index.rst
0 → 100644